
Este es un post que la verdad no había tenido en mente crear pero últimamente se me ha convertido en una necesidad y la verdad he disfrutado hacer y es que en estos ya casi 5 años involucrado en temas relacionados con Big Data y la nube la verdad es que he podido notar como construir un proyecto Spark desde cero se convierte en algo fácil pero netamente basado en copiar y pegar de proyectos anteriores, pero … y qué sucede cuando no hay un proyecto anterior jejeje, pero no es el único caso y qué sucede con aquellos que están aprendiendo, es cuestión de indagar por Internet y encuentras 30 formas distintas de armar un proyecto desde cero de Spark con Scala con Maven y en un IDE en este caso IntelliJ, pero cual es la idónea, cual es la que verdaderamente funciona.
Pues he decidido crear un esqueleto de proyecto (el cual espero poder ir evolucionando y mejorarlo) que seguramente no es la mejor pero desde mi humilde punto de vista es funcional.
Configurar el IDE
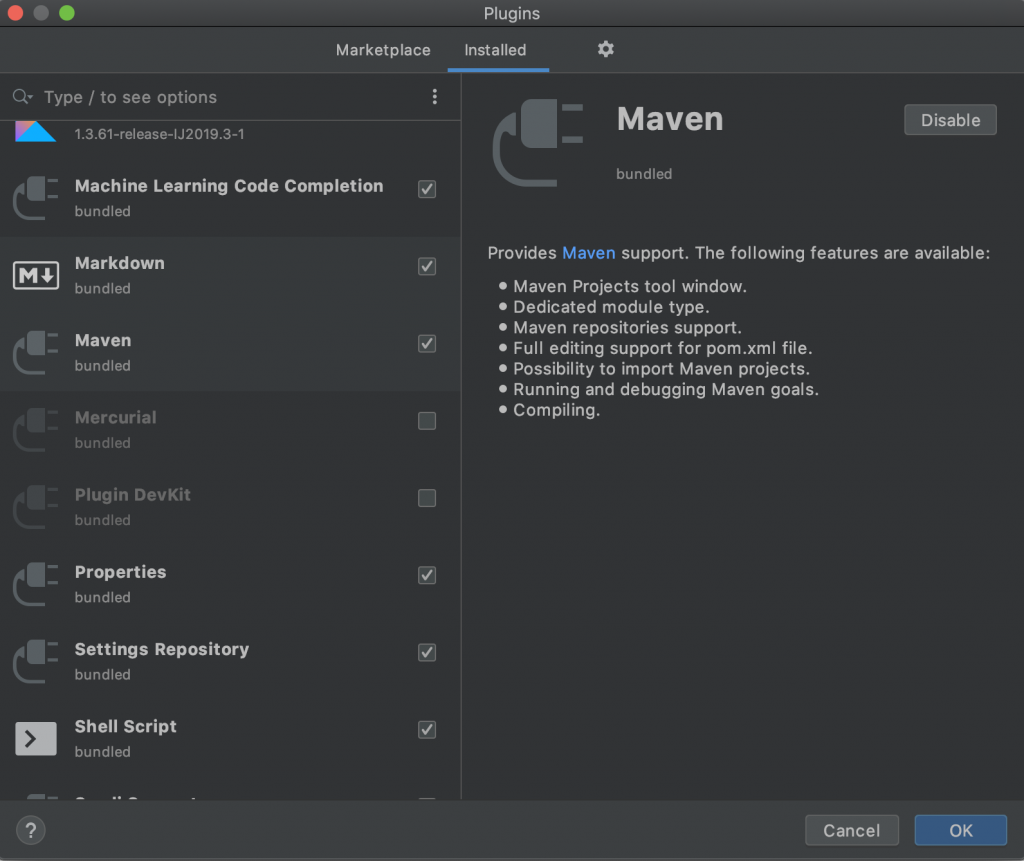
Lo primero antes que nada es instalar el jsdk (1.8 como mínimo), luego en la instalación o inmediatamente después es asegurarnos de contar con los plugins de Maven y Scala, para ello en la ventana de inicio vamos a los plugins.

Buscamos el plugin de Scala para verificar que este instalado si no lo está lo instalamos y luego en la misma ventana en la parte superior junto a Marketplace hacemos clic en installed y verificamos que el plugin de maven por defecto este habilitado.

Creamos el proyecto
Seleccionamos la opción de crear un nuevo proyecto.

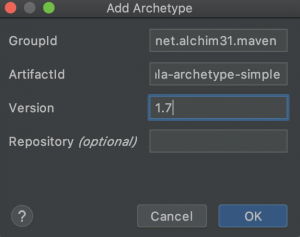
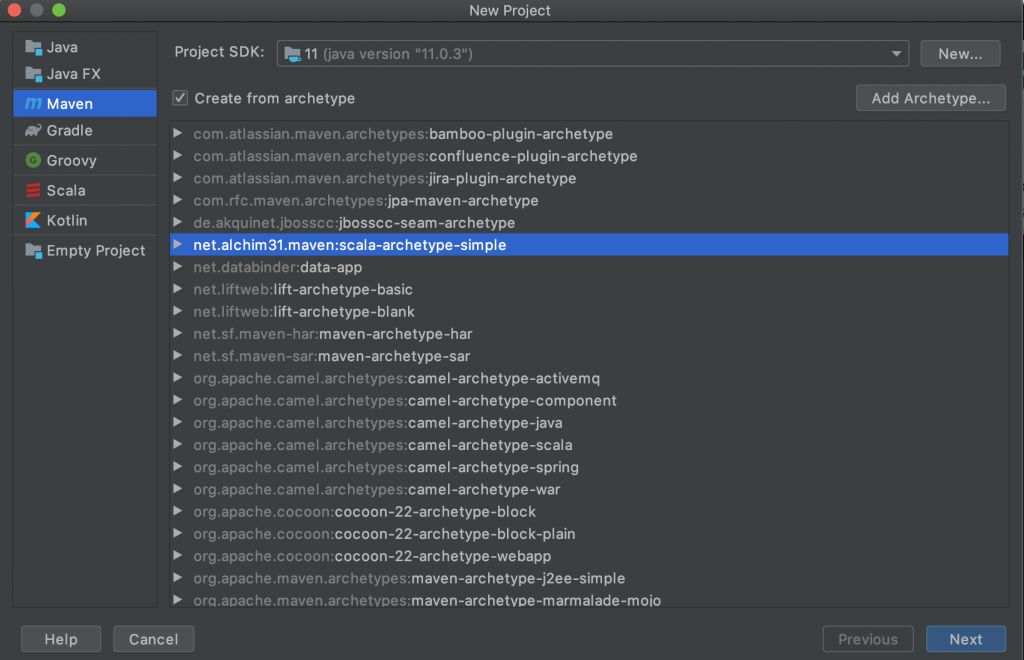
Acto seguido seleccionamos la opción de proyecto maven y marcamos la opción de Create from archetype. Seleccionamos el archetype net.alchim31.maven:scala-archetype-simple y pulsamos el botón «Next». Si el archetype no existe pulsamos el botón de Añadir Archetype (Add Archetype) cumplimentamos la información con los siguientes datos:
GroupId: net.alchim31.maven
ArtifactId: scala-archetype-simple
Version: 1.7
Una vez añadido lo seleccionamos y como habíamos indicado antes pulsamos el botón «Next».
Inmediatamente después le daremos nombre a nuestro proyecto y si queremos ser más específicos indicamos el GroupId, ArtifactId y versión de nuestro proyecto (OJO esto último es opcional), pulsamos «Next» y por último en la ventana resumen pulsamos «Finish».
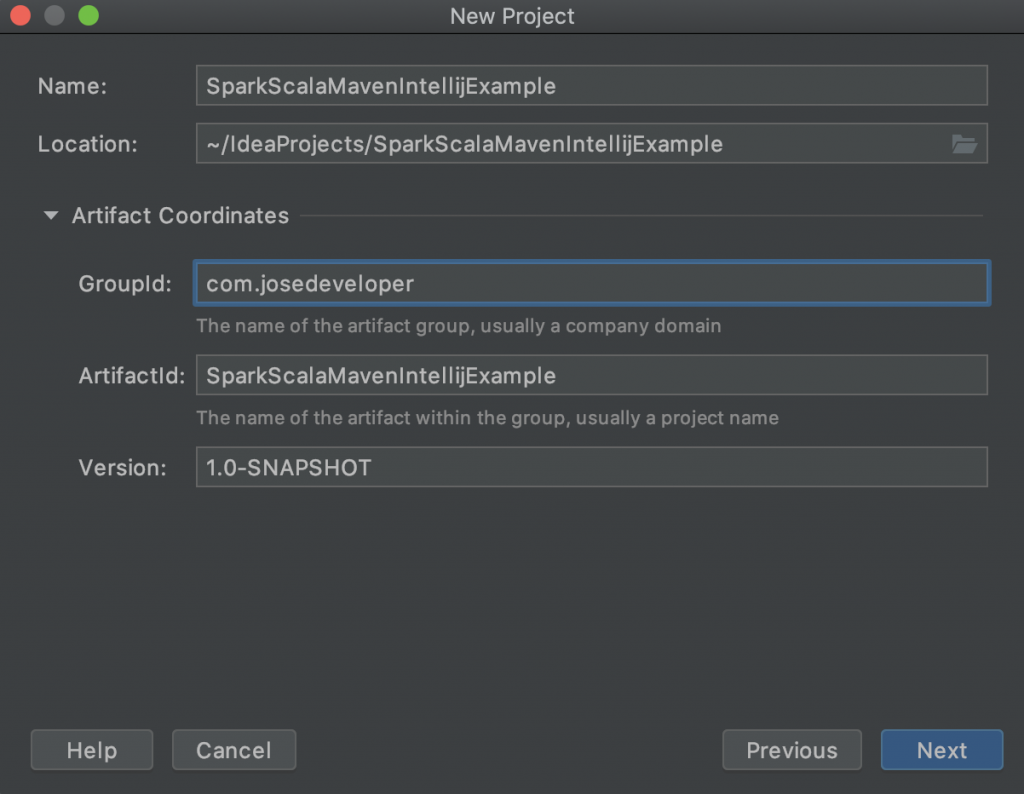
Lo primero que deberemos hacer para que nos facilite la tarea será habilitar la autoimportación de las dependencias maven como señalamos en la imagen.
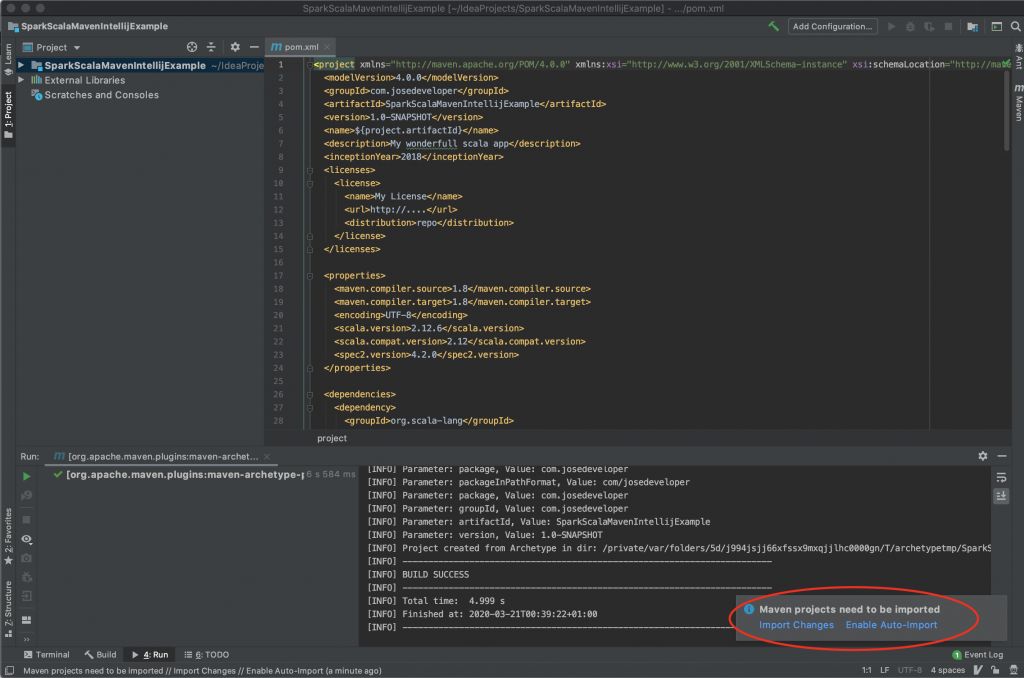
El construir el proyecto a partir de un archetype (arquetipo) maven consiste en armar el esqueleto de un proyecto a partir de una plantilla definiendo una estructura minima por defecto, por lo cual veremos un fichero pom.xml (gestión de dependencias maven) con algunas dependencias y una estructura de carpetas para el código fuente y pruebas unitarias, con ficheros incluidos.
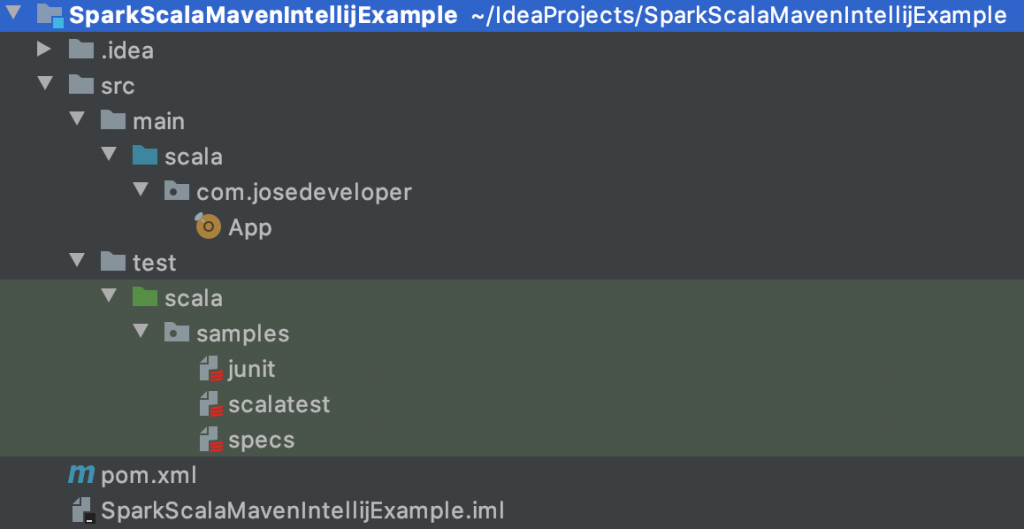
Aprovechamos de dar un vistazo a la clase App y a las pruebas unitarias que por defecto nos añade al proyecto e incluso podemos compilar el proyecto para contrastar que todo está de maravilla y para ello solamente necesitamos hacer clic en la pestaña maven ubicado en la parte derecha, donde aparece el nombre de nuestro proyecto desplegar lifecycle y hacer doble clic en compile y esto iniciará el proceso de compilación terminando exitosamente.
Añadimos dependencias
Ya estamos llegando al final, ahora lo que haremos será añadir al fichero pom.xml las dependencias spark que utilizaremos para este ejemplo. Empezaremos por editar las propiedades quedando estas así:
|
1 2 3 4 5 6 7 8 9 |
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.12.6</scala.version> <scala.compat.version>2.12</scala.compat.version> <spec2.version>4.2.0</spec2.version> <spark.version>2.4.5</spark.version> </properties> |
Añadimos las dependencias de spark al conjunto de dependencias existentes
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.compat.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.compat.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> |
Por último modificaremos nuestra clase App quedando esta así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
package com.josedeveloper import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession /** * @author ${user.name} */ object App { def main(args : Array[String]) { val spark:SparkSession = SparkSession.builder().master("local[1]") .appName("SparkByExamples.com") .getOrCreate() val rdd:RDD[Int] = spark.sparkContext.parallelize(List(1,2,3,4,5)) val rddCollect:Array[Int] = rdd.collect() println("Number of Partitions: "+rdd.getNumPartitions) println("Action: First element: "+rdd.first()) println("Action: RDD converted to Array[Int] : ") rddCollect.foreach(println) } } |
Para de nuevo volver a compilar el proyecto, que deberá culminar exitosamente.
Ejecución
La forma que indicaremos para la ejecución de los jobs desde IntelliJ no es la mejor pero es una forma sencilla y funcional para probar cosas y sobre todo para quien comienza a hacer tests sin necesidad de empaquetar y crear un jar y desplegarlo en una máquina virtual o en un cluster. ¿Cuál sería entonces la mejor forma? A mi modo de ver las cosas la mejor forma sería mediante prueba unitarias y de integración donde podamos probar todo el job de inicio a fin y para explicarles como ya tengo en mente preparar otro post paso a paso indicando como hacerlo y las herramientas para lograrlo. Continuando con la configuración de la ejecución, si sencillamente con botón derecho del ratón hacemos clic en Run ‘App’ nos arrojará el error.
Exception in thread «main» java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at com.josedeveloper.App$.main(App.scala:13)
at com.josedeveloper.App.main(App.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:583)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:521)
… 2 more
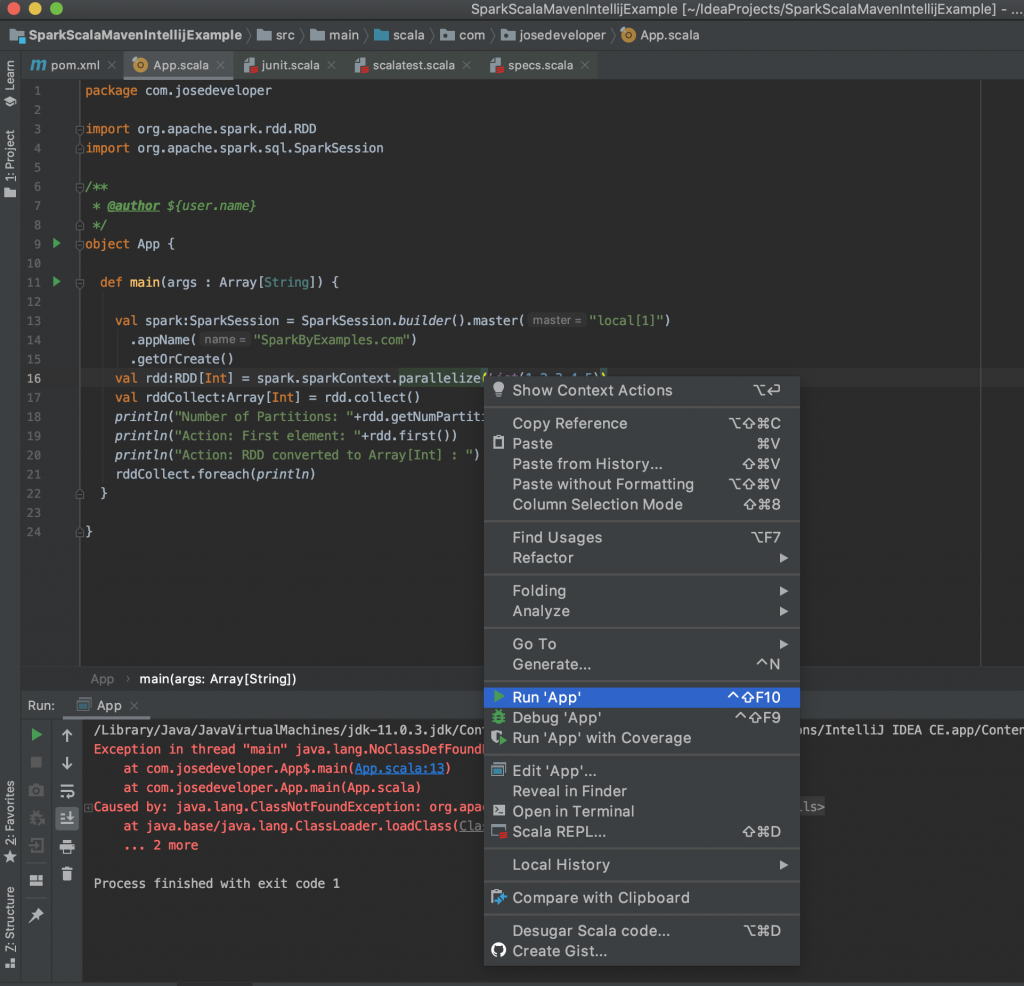
El error se debe a que no encuentra las clases con las que fue compilado previamente y eso se debe a que las dependencias de spark las hemos añadido con el alcance «provided».
¿Por qué provided? Debido a que en un entorno empresarial esas dependencias no debemos agregarlas ya que las provee la infraestructura Big Data de la empresa.
Entonces para solventar el error sencillamente debemos ir al menu «Run» y hacemos clic en «Edit Configurations» y allí marcamos la opción de incluir dependencias provided (Include dependencies with «Provided» scope).
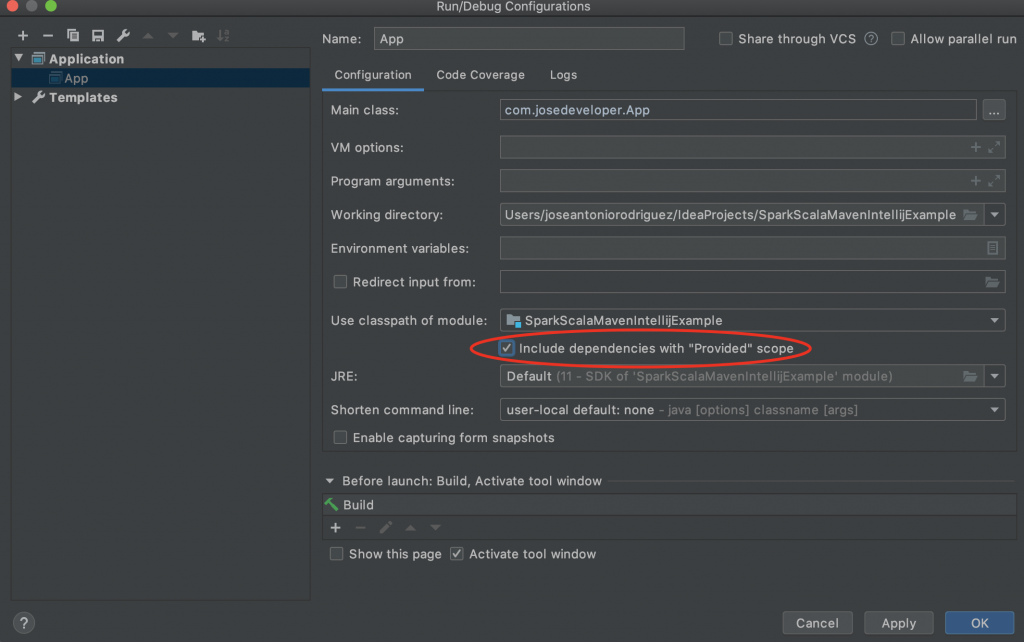
Hecho eso volvemos a ejecutar la clase App y veremos como si se logra ejecutar la aplicación. Sin más espero que les haya servido de ayuda y les comento que mi próximo paso será crear un archetype (arquetipo) y a su vez explicarles como hacerlo para que cada quien pueda construir uno acorde con las necesidades de su organización y así dotamos de más profesionalidad y agilidad nuestro trabajo y evitamos el copiar+pegar donde en ocasiones terminamos añadiendo mas dependencias y plugins innecesarios así como también arrastrando problemas y errores (de haberlos).
Aquí les dejo el video
Repo GitHub



