Seguro que en alguna ocasión nos ha tocado hacer un SHOW PARTITIONS de una tabla HIVE particionada, con la finalidad (para quien no lo sepa) de obtener/visualizar las particiones existentes de los datos. Hasta aquí nada nuevo, pero lo que quiero mostrarles en esta oportunidad es un método (nada espectacular) que me ha servido mucho donde obtengo las particiones de una tabla (Hive) y los usos que le he dado al método, entre otras con grandes ventajas en performance.
Como seguramente muchos de ustedes saben si invocamos un SHOW PARTITIONS en spark por ejemplo en la spark-shell, esta nos devuelve un DataFrame con una única columna, como el siguiente ejemplo:
|
1 2 3 4 5 6 7 8 9 |
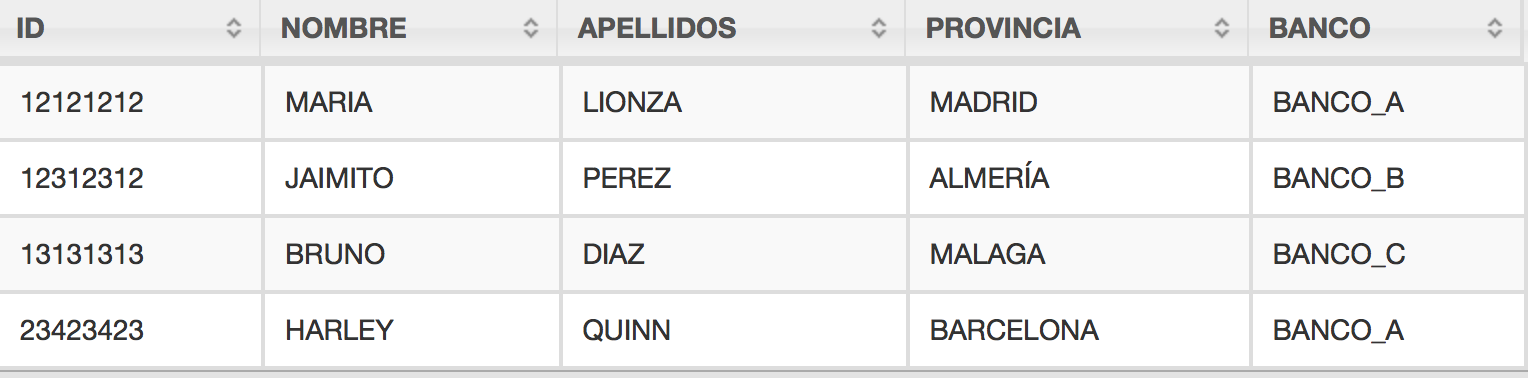
+--------------------------------------------------------------------------+ |partition | +--------------------------------------------------------------------------+ |country=VENEZUELA/state=BOLIVAR/city=GUAYANA/dt=20191012/hour=1020 | |country=VENEZUELA/state=DISTRITOCAPITAL/city=CARACAS/dt=20191012/hour=1200| |country=VENEZUELA/state=CARABOBO/city=VALENCIA/dt=20191012/hour=1700 | |country=VENEZUELA/state=CARABOBO/city=VALENCIA/dt=20191012/hour=1750 | |country=VENEZUELA/state=MERIDA/city=MERIDA/dt=20191012/hour=1400 | +--------------------------------------------------------------------------+ |
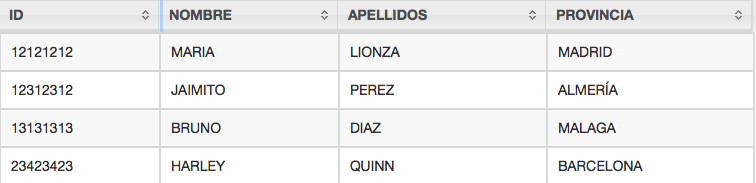
Con mi método lo que hago es transformar el DataFrame original en uno formateado donde cada variable de particionado es una columna. A continuación el método y el que sería el DataFrame resultante
|
1 2 3 4 5 6 7 8 9 |
+------------------------------------------------+ |country |state |city |dt |hour| +------------------------------------------------+ |VENEZUELA|BOLIVAR |GUAYANA |20191012|1020| |VENEZUELA|DISTRITOCAPITAL|CARACAS |20191012|1200| |VENEZUELA|CARABOBO |VALENCIA|20191012|1700| |VENEZUELA|CARABOBO |VALENCIA|20191012|1750| |VENEZUELA|MERIDA |MERIDA |20191012|1400| +------------------------------------------------+ |
Ahora ustedes se preguntarán y que hay de fascinante o interesante en este método. La verdad que el método en sí aporta poco es sencillamente una simple transformación pero para mí la magia reside en para que lo utilizo y es lo que les quiero contar.
Imaginen que la tabla que posee las 5 variables de partición (ni discutamos si es acertado poseer 5 variables de particionamiento) posee un sin fin de particiones y que a su vez para una misma ciudad en una misma fecha hay varias particiones por hora (como aparece en el ejemplo para la ciudad de Valencia) y cada partición a su vez tiene muchos registros. Con este supuesto si quisiéramos hacer una consulta para obtener la máxima partición (la más reciente) para una fecha, ciudad, estado y país en especifico podríamos llegar a tener problemas de TimeOut o SocketTimeOut ya que:
* El cluster se vería exigido intentando trabajar sobre las particiones pertinentes (debido al gran número de particiones).
* Una vez obtenidas las particiones cargar los datos desde HDFS y recorrer de forma innecesaria un conjunto de datos requiriendo mucho más memoria de la necesaria.
¿Recorrer de forma innecesaria?
Si, ya que recorreríamos un conjunto de registros donde muchos de esto compartirán el valor de la columna «hora» (partición) y apegándonoslos al ejemplo de arriba (la ciudad de Valencia) realmente los valores posibles serían 2:
* 1700
* 1750
Solución: Pues al obtener el DataFrame de particiones, si posteriormente filtramos por país, estado, ciudad y día solo nos quedarían 2 registros para el campo hora y sencillamente tendría que hallar el máximo valor de 2 registros en vez de tener que cargar datos de HDFS e iterar sobre todos estos.
¿Mucha más memoria de la necesaria?
Si, ya que al hacer un SHOW PARTITIONS, nosotros interactuamos con el metatstore y los metadatos en vez de trabajar con todos los datos de HDFS con todo lo que eso implica en cuanto a latencia, debido a la necesidad de ir a disco, etc.
¿Existe alguna otra ventaja de trabajar con el metastore?
Si, por ejemplo para hallar la máxima partición, trabajando únicamente con el DataFrame de particiones y una vez hallada la partición idónea, digamos que la más reciente, entonces construyo la consulta (muy especifica) indicando los valores de la partición deseada evitando esos errores de TimeOut haciendo uso eficiente de los recursos. De hecho yo lo que hecho es construir un WHERE dinámico (quizás lo comparto en la próxima entrada) a partir del DataFrame de particiones filtrado.
¿Se te ocurre otra ventaja de utilizar un método como este e interactuar con el metastore? ¿Habías hecho algo similar para tener mejoras de rendimiento y uso eficiente de recursos?
Espero que les sea de utilidad.