A continuación están listados todos los presupuestos aportados y que serán votados en reunión extraordinaria el día jueves 7 de marzo.
Presupuesto Asiem -> Descargar
Presupuesto J A García -> Descargar
Presupuesto ASESORES MCM -> Descargar

Finalmente ha llegado a mi correo mi certificación de Databricks Spark 3.0 tras haber aprobado dicho examen. El examen lo presenté el 14 de abril del 2021 y les voy a contar brevemente como fue el examen, de qué trata y qué hice para aprobarla.
El examen
Las características del examen son las siguientes:
OJO: No olvides días previos al examen entrar a la Web del examen y culminar el alta, que consiste en un software que reconoce tu rostro. NO LO DEJES PARA ÚLTIMO MOMENTO.
El examen consta de únicamente preguntas de selección múltiple, aunque eso si, no todas van de conceptos, las preguntas dada mi experiencia se componen de:
Las preguntas
Tal cual como lo indica la página dedicada a la certificación el contenido a evaluar es:
|
1 2 |
spark._.format(_).options(header='true') ._('zipcodes.csv') |
Donde las opciones a escoger serían:
La plataforma te permite marcar preguntas para ser revisadas más adelante, cosa que yo aconsejo utilizar, hacer una pasada rápida por las preguntas, selecciona una respuesta y sobre aquellas que se tenga una mínima duda sencillamente se marca y le das una revisión, de esta forma tendrás oportunidad de responder todas las preguntas y revisar en 2 o hasta 3 ocasiones todas las preguntas que hayas dejado marcadas.
Finalizado el examen
Tan pronto finalizas el examen podrás observar por pantalla una valoración no definitiva del resultado de la prueba y minutos después recibirás un correo con la nota, donde ya te indican si aprobaste (o no, pero si sigues mi receta aprobarás) y luego pasados unos 7 días hábiles o quizás un poco menos recibes tu certificado por correo.
Receta para aprobar el examen

Ahora es tu turno, te animas a afrontar este reto, tienes alguna otra certificación en mente, estás indeciso en cual certificación de Spark tomar o si por el contrario ya presentaste está o alguna otra certificación cuéntanos qué tal te fue.
Muchos de los que me conocen saben que soy fiel a las certificaciones y como siempre digo, no es el papel con el aprobado lo que importa sino todo el proceso de prepararse para presentar y aprobar el examen lo que realmente vale, ya que es durante este proceso que empezamos a conocer, a meternos en las entrañas de un software, lenguaje de programación o plataforma, es decir, sencillamente salimos de nuestra zona de confort y empezamos a hacernos preguntas fuera de lo común y buscamos sus respectivas respuestas (de haberlas) o buscamos soluciones alternativas (también de haberlas), todo eso deriva en APRENDIZAJE.
Insisto me encantan las certificaciones pero porque para mí significan plantearme un reto y demostrarme a mí mismo que soy capaz de seguir aprendiendo, que si puedo aprender un nuevo lenguaje, que todavía tengo la fuerza y las ganas de superación para actualizarme en alguna tecnología en especial. Con el pasar del tiempo les confieso que cada vez se me ha hecho más difícil el intentar plantearme un reto de este tipo, por razones como la escasez de tiempo, la cantidad de trabajo, o el aprender en un marco muy estricto, pero creo que ya ha llegado la hora de proponerme otro de esos retos y que ya les contaré si lo consigo o no y es preparar la certificación Databricks Certified Associate Developer for Apache Spark 3.0. Por qué esta certificación y no otra:

A su vez una razón de peso para mí es que al presentarla y aprobarla, esto motive a la gente que trabaja conmigo para que a su vez sientan ese deseo por aprender y especializarse e incluso no comentan los mismos errores que yo y que al menos ya cuenten con algo de material de apoyo para empezar.
El material de referencia que utilizaré para prepararme serán los libros:
A su vez sigo el blog de Databricks que cada tanto comparte información importante sobre todo referente a cómo funciona Spark.
Por último he comenzado a crear una serie de notebooks con ejemplos muy simples (tanto en Scala como Python) que comparto con todos intentando abarcar todo el contenido.
Aquí les dejo el enlace espero que sea de ayuda y les motive a aprender y afrontar esta certificación e incluso les motive a seguir. Este mes es mi cumpleaños y dudo que me dé una paliza repasando pero quizás (y por eso lo comparto para crear una especie de compromiso) me disponga a presentar en abril y espero poder aprobar a la primera.
Quienes me conocen saben que soy fan de IntelliJ, ya llevo unos cuantos años desde que dejé de usar eclipse y la verdad es que estoy encantado con la decisión que tomé, para mí es la mejor herramienta para desarrollo Java, Scala (y supongo que Kotlin).
Actualmente Spark está en mi día a día ya sea a modo desarrollo programando en Scala, razón por la cual uso continuamente IntelliJ sino también en la formación tanto en Scala como en Python, hasta hace poco para las formaciones de PySpark (entiéndase Spark con el API de Python) utilizaba los Jupyter notebooks (e incluso la plataforma de Databricks pero eso da para otra entrada en el blog) pero estaba la curiosidad que poco a poco se ha convertido en una necesidad de contar con una herramienta más potente que permitiese hacer debug, que integrase Git, hacer markdown, autocompletado de código, permita estandarizar el código, etc. Si lo meditan un poco casi todo de una forma u otra se puede alcanzar con los Jupyter notebooks, pero lo que cambia es la forma de programación, ya que con un IDE sería programación al uso (sea esta funcional o no), mientras que con los notebooks sería programación literaria, es decir, un entorno más enfocado a la explicación y documentación del código y hoy en día ampliamente utilizado por científicos de datos (data scientists), mientras que el primero (IDE) más utilizado por los ingenieros de datos (data engineer).

Finalmente nos hemos puesto manos a la obra en probar varios IDEs en el equipo y yo no quise desperdiciar la oportunidad de trastear con PyCharm y hacer mis primeras pruebas de programación de PySpark y es lo que comparto ahora con ustedes.
Antes que nada hay ciertos requisitos previos:
Está vez no les voy a mostrar como instalar Spark, ya que hay muchísimas fuentes que nos explican como hacerlo pero en cualquier caso hay que tener claro que es necesario Java 8 (al menos) y declarar las variables de entorno SPARK_HOME y HADOOP_HOME, la primera apuntando a la ruta de la instalación de Spark y la segunda a la ruta base de donde se instalará el winutils.
El otro requisito es Python, hay distintas formas de instalar python que tampoco explicaré aquí, pero resumiendo puede ser instalando el lenguaje (y luego pip si se desea o es necesario instalar otra dependencia) o mediante anaconda, yo he elegido este último ya que es un entorno que trae consigo ya instalado jupyter notebooks además de otras herramientas, en cualquier caso si alguien tiene cierta curiosidad de cuando instalar pip o anaconda les dejo este articulo de stackoverflow que no tiene desperdicio.

Ya entrando en materia, el primer paso es descargar e instalar PyCharm (este podría incluso llegar a instalarse desde Anaconda, yo preferí descargarla para contar con la versión mas reciente). Yo lo hice con la versión community
Una vez instalado y ejecutado por primera vez, crearemos un nuevo proyecto y deberemos especificar nuestro entorno (environment), yo soy de los que prefiere crear un entorno por proyecto debido a que cada proyecto python (en general) puede ser diferente en cuanto a dependencias características, etc. llegando incluso a diferir la versión de python entre 2 y 3. A su vez dejo marcada la opción de que genere un main.py tal cual como aparece en las imágenes.

El IDE nos genera un main.py que hace de esqueleto de la aplicación, lo editamos con un trozo de código que genera un DataFrame y mostrará parte de su contenido mediante la invocación del método show quedando de esta manera
# This is a sample Python script.
# Press ⌃R to execute it or replace it with your code.
# Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press ⌘F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('PyCharm')
try:
#import findspark;
#findspark.init()
from pyspark import SparkContext, SparkConf
except ImportError:
raise ImportError("Unable to find pyspark -- are you sure SPARK_HOME is set?")
import random
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PyCharm Example") \
.getOrCreate()
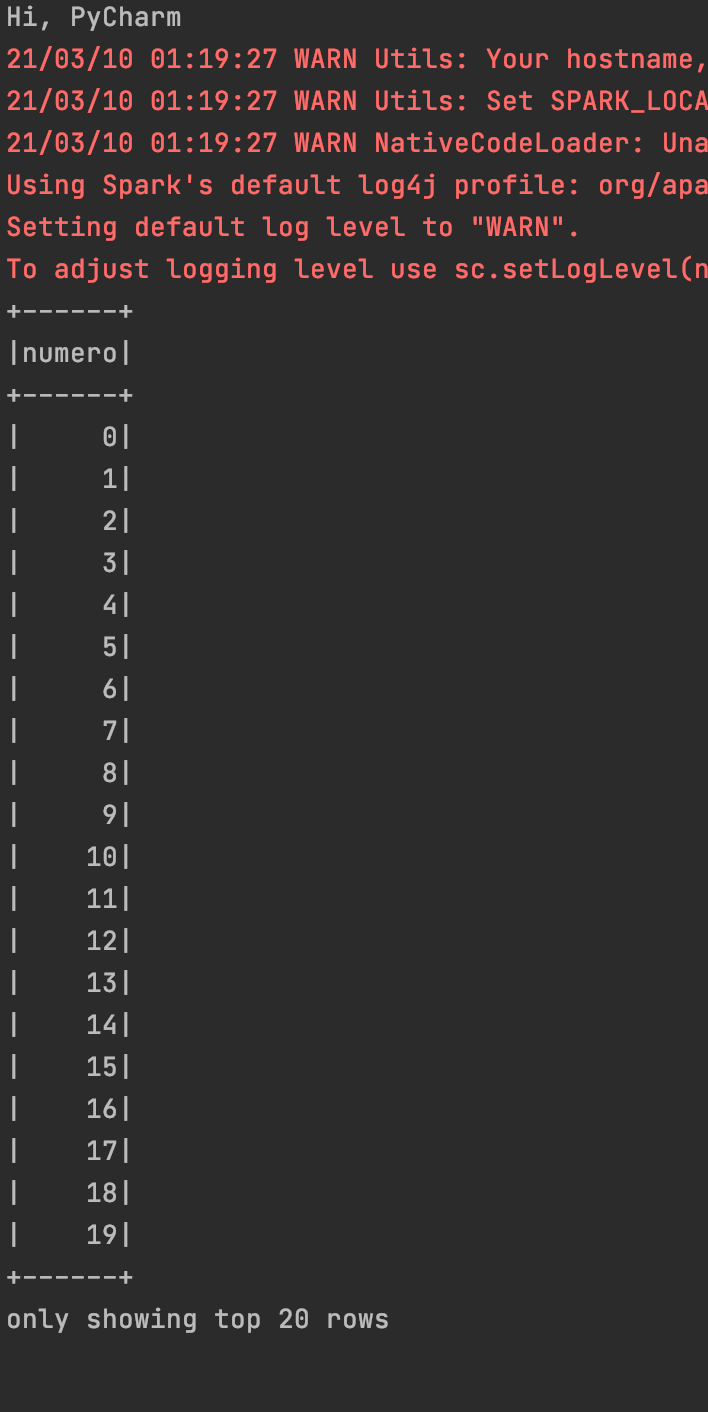
mi_rango = spark.range(1000).toDF("numero")
mi_rango.show()
# See PyCharm help at https://www.jetbrains.com/help/pycharm/
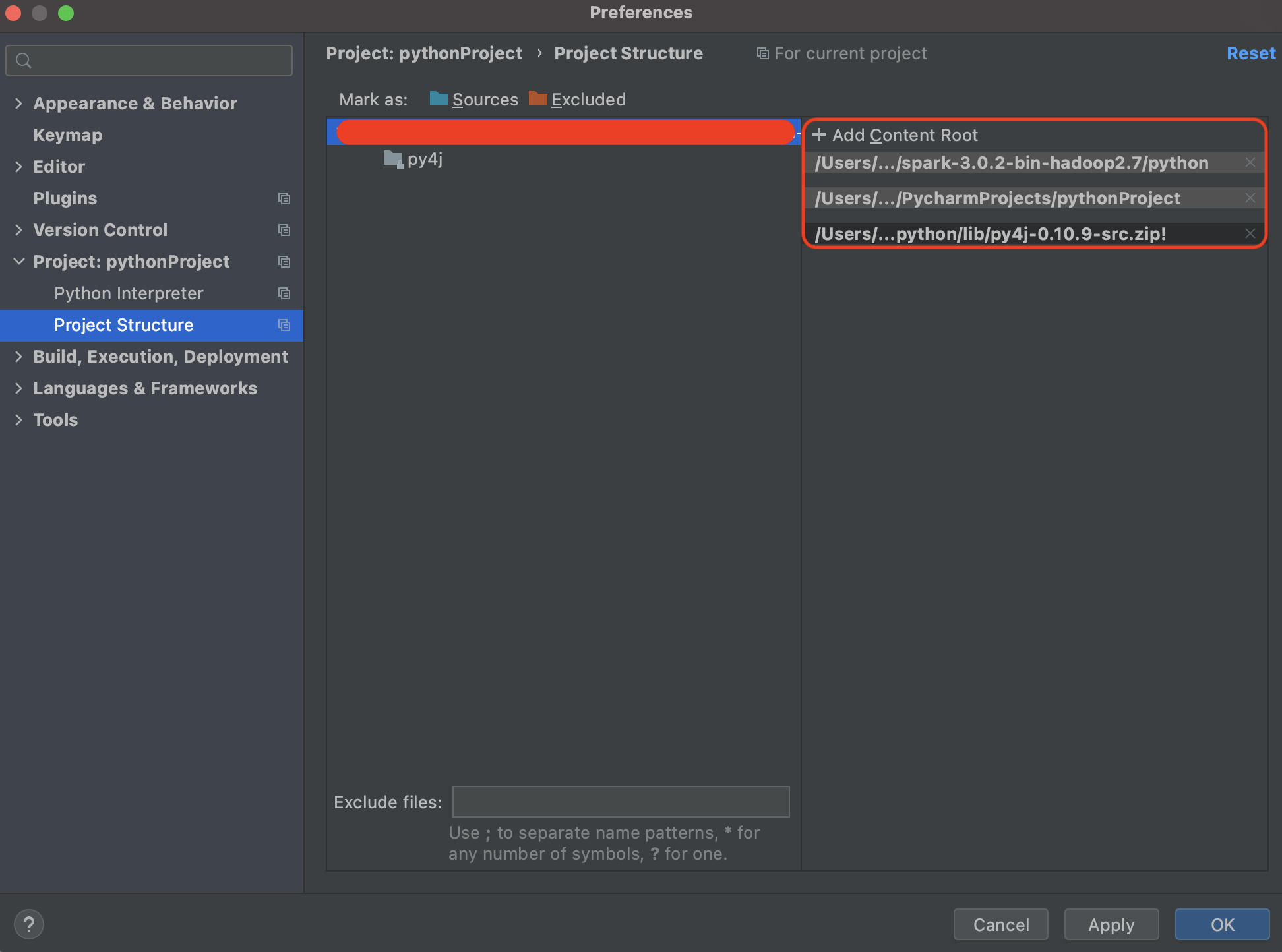
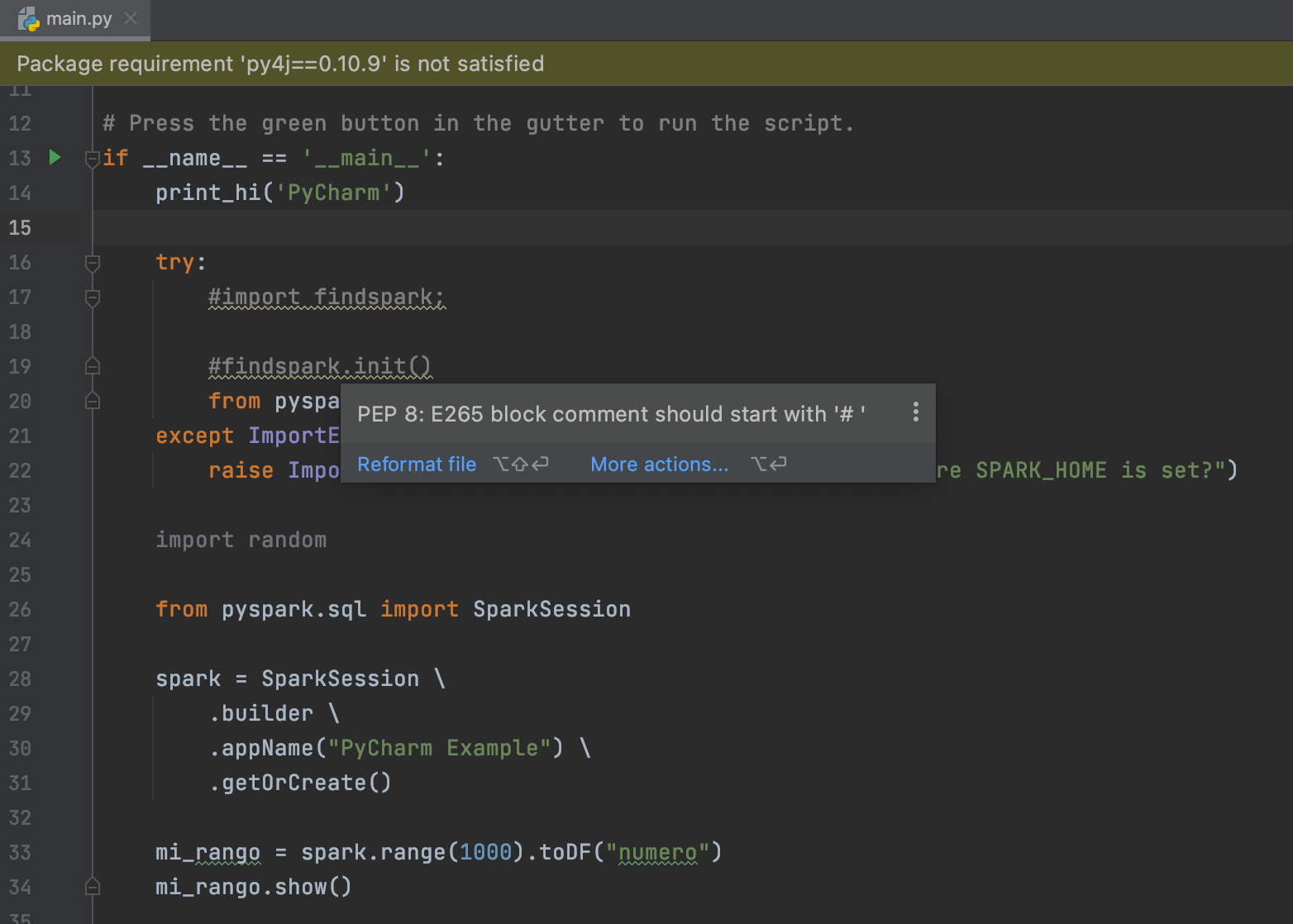
El añadir py4j es una de las alternativas que existen para poder hacer ejecuciones en local del código. Otra alternativa es instalar py4j como dependencia del entorno (environment) y de hecho la misma herramienta te ofrece la alternativa como se refleja en la imagen a continuación
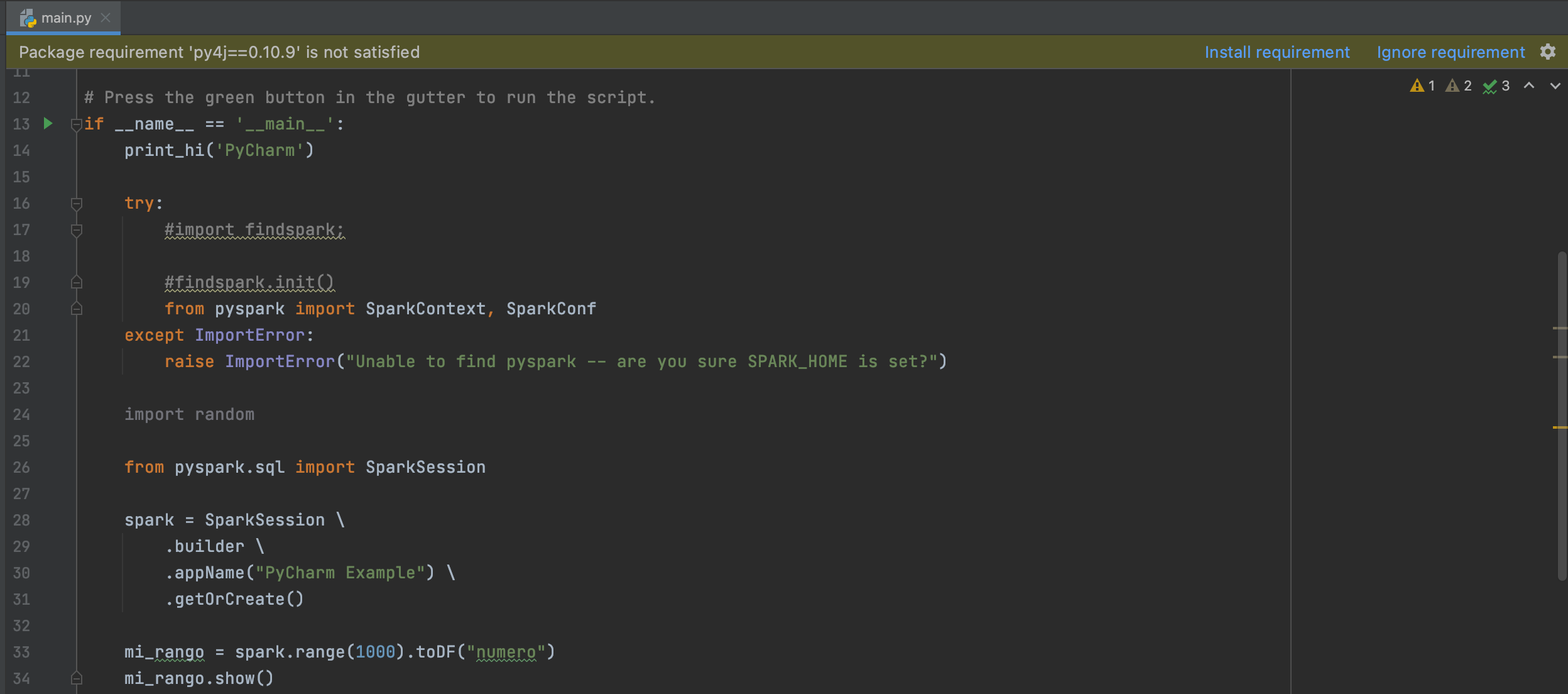
Ahora podemos darnos cuenta que ya no se resaltan (en rojo) parte del código. Procedemos de nuevo a ejecutar el código y nos damos cuenta que este se ejecuta exitosamente.
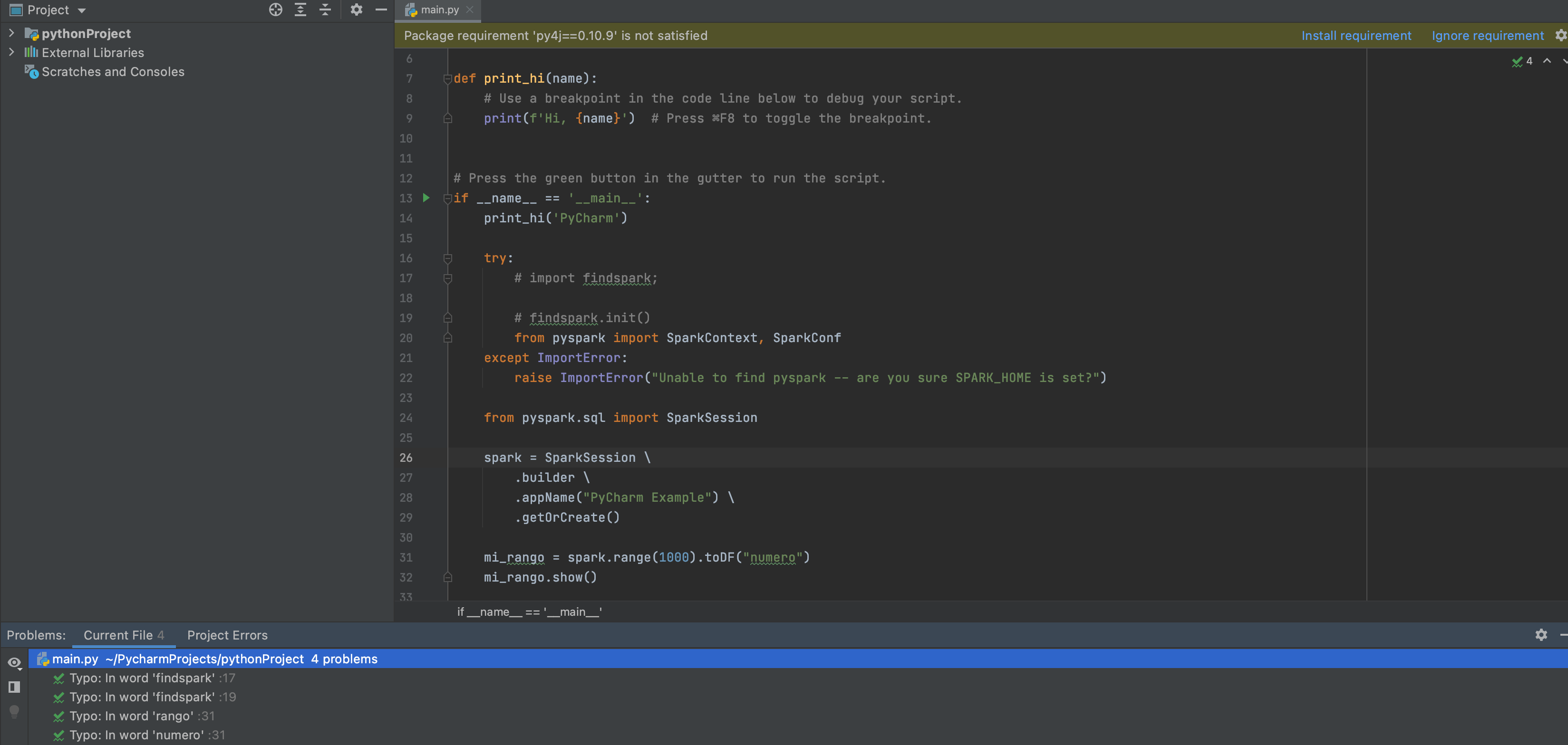
Ya estamos a punto de terminar pero falta un pequeño detalle, el IDE todavía nos marca unos warnings, por ejemplo el código comentado y esto se debe a que por defecto PyCharm ya aplica PEP8 como estándar al código y por ende todo aquello que no cumpla con el estándar definido será resaltado para su corrección como se muestra en la imagen.
Incluso si hacemos clic en el símbolo de warning (cuidado) ubicado en la parte superior derecha, nos listará las cosas a mejorar que cumplan con el estándar. Una vez listado los warnings procedo mejorar el código quedando de la siguiente manera
Finalmente el código (aunque es muy simple) ya cumple con el estándar PEP8 y nos ha resultado relativamente sencillo poder ejecutar nuestro código desde el mismo IDE, además la herramienta nos permite sin salir de ella acceder a linea de comandos, hacer control total de Git (pull, push, commit, comparación entre ramas y más), poner breakpoints y realizar debug del código. Otra cosa a comentar es que aun cuando no hayamos definido el SPARK_HOME (cosa que no recomiendo) y el HADOOP_HOME, estas variables podemos definirlas antes de ejecutar el código mediante Edit Configurations.
Ha sido un ejemplo muy simple pero creo que refleja parte del potencial de la herramienta, aunque no todos son buenas noticias, por ejemplo la versión community no permite abrir y ejecutar jupyter notebooks cosa que si permite la versión de pago, llegando incluso a permitir la ejecución celda a celda y esta es una característica muy deseada que algunas herramientas si lo permiten como es el caso de VSCode, sin embargo esto no empaña para nada las capacidades que tiene y puede aportarnos de cara a la productividad.

Hola a todos, muchísimo tiempo sin escribir y no es que no quiera sino que la vida con hijos lo convierte en una tarea en mi caso algo difícil de compaginar. Hoy después de año y medio quiero compartir mi receta para aprobar la certificación AWS Certified Big Data – Specialty.
No les voy a mentir es una certificación complicada quizás un poco más complicada que la AWS Certified Solution Architect – Associate pero lejos de ser imposible, su complejidad desde mi punto de vista radica en que hay que tener un conocimiento amplio no solo en los servicios de AWS sino de frameworks y herramientas utilizadas hoy en día en Big Data.
La AWS Certified Big Data – Specialty es una certificación que puede tomarse de buenas a primeras, es decir, no tiene como requisito el haber aprobado previamente alguna otra certificación aunque desde la misma página de la certificación nos hacen unas sugerencias que desde mi punto de vista son con razón y son las siguientes y cito:
El examen de certificación dura 170 minutos y tiene un costo de 300$ y está disponible únicamente en ingles, japonés, coreano y chino.
Vamos al gramo ¿cómo preparé el examen? Bueno para esto compré 2 cursos ambos muy buenos (excelentes) y amplios y abarcan diría que más de un 90% del contenido a evaluar y casi todos los servicios de amazon, quizás queda alguno por fuera como por ejemplo Storage Gateway, Cloudfront, Elastic Load Balancer, EC2 pero es aquí donde toma relevancia el haber aprobado previamente otra certificación lo cual nos «aseguraría» tener conocimientos en esos otros servicios. Los cursos en cuestión son:
También hice algún curso de la página de aws.traning donde desde AWS nos plantean distintos learning path (caminos de aprendizaje?)

Otra cosa que hice fue redactar mi propio material y para ello revise las F.A.Q. de todos los servicios relacionados con la certificación y los limites y con toda esa información redacte mi chuleta (utilicé evernote) la cual iba enriqueciendo mediante aspectos importantes que veía en los cursos antes indicados y de interrogantes que me iba planteando en el camino y que iba dándole solución luego al comprobarlo de forma practica o investigar en la misma documentación de AWS. ¿Qué servicios mirar? les diría que los principales son: Redshift, EMR, Kinesis (streams, firehose y analytics), DynamoDB, S3, Glacier, Snowball, RDS, DMS, Machine Learning, SageMaker, Athena, Elasticsearch service, IoT, CloudTrial, CloudWatch, Lambda y Glue. Además de estos puede que salgan preguntas que involucren SQS, SNS, EC2 (tipos de instancias), Storage Gateway, Direct Connect, rekognition, polly y lex.
También aproveche de ver varios vídeos desde los canales de youtube:
Lo interesante de ambos canales es que plantean solución a distintos escenarios mediante la combinación y uso de distintos servicios de AWS lo que nos permite tener una perspectiva real de como afrontar e integrar muchos de estos servicios, casos de uso, buenas practicas entre otras cosas y el último de los canales también posee los vídeos de las sesiones re:Invent de los años 2017, 2018 y aunque alguno de los videos puede llegar a durar 1 hora, pues a mí que lo que mas me hace falta es el tiempo lo que hacía era verlos a velocidad de 1.25X (esta técnica también la aplicaba para ver los vídeos de Udemy y acloud.guru).
Hice el test de 10 preguntas de la certificación que se puede encontrar en el siguiente enlace. De antemano les digo que no se dejen intimidar por este examen, estas 10 preguntas desde mi punto de vista son muy difíciles y la realidad es que la mayoría de preguntas en el examen de certificación ni son tan difíciles ni tan largas. Sin embargo esto me sirvió para profundizar en cuanto a contenidos y sobre todo a plantear una estrategia de cara al examen, la cual se las comentaré más adelante.
Les debo confesar que las preguntas de ejemplo me dejaron un poco tocado así que compre los test prácticos de Whizlabs. Hice el test gratuito y me decidí a comprarlo definitivamente.
¿Cuál fue mi estrategia?
Mi estrategia fue la siguiente. Practicando con los 3 tests de Whizlabs, me propuse intentar resolver las 65 preguntas en un plazo de 60 minutos, es decir, daba una lectura muy rápida a las preguntas y daba una respuesta, de esta manera me aseguraba que todas las preguntas fueran contestadas (el examen no tiene factor de corrección) y todas aquellas preguntas donde me quedara duda (casi todas) las marcaba para su posterior revisión, de esta forma logré poder dedicar mucho tiempo a la revisión de las preguntas.
Finalmente comentarles que el resultado fue positivo, obtuve un 74% en la prueba y con este resultado mi premio la certificación, pero lo más valioso es todo lo aprendido en el camino, ahora mismo conozco muchos de los servicios de amazon y he trasteado con ellos y por supuesto tengo una idea «clara» de como integrarlos para dar soluciones.

TIP final: Existe la opción de obtener 30 minutos más para el examen y consiste en solicitar «Request Exam Accommodations» al programar un examen al no ser el inglés tu lengua materna. He aquí un enlace de como hacerlo.
Espero que mi receta les ayude a conseguir el objetivo de aprobar la certificación y para aquellos que dudan en afrontar este reto, que sepan que es un objetivo alcanzable y que no solo les llevará a aprender mucho sino que desde el punto de vista curricular les aportara valor, tanto es así que existe un grupo de LinkedIn de únicamente personas certificadas por lo cual esos perfiles obtienen mas visibilidad.
Entonces ¿te animas a presentarla? y tu que ya presentaste cuéntanos cual fue tu receta para aprobar la certificación