¿Qué es apache drill?
Es un motor de consultas open-source para exploración de fuentes de datos con grandes volúmenes de datos. Apache drill nos permite realizar análisis de alto rendimiento sobre datos semiestructurados sin dejar de ofrecer la familiaridad y el ecosistema de la norma ANSI SQL. Apache drill a su vez posee integración con Hive y HBase.
Apache drill a menudo es comparado con Hive y con Impala, por su alto rendimiento por trabajar con ficheros .csv y .json, así como también porque por medio de estas podemos efectuar consultas en HBase, pero hay un aspecto donde drill sobresale y es que puede conectarse a otros gestores de bases de datos como por ejemplo MySQL y MongoDB.
¿Cómo conocí Apache drill?
Me topé con apache drill por casualidad en el 2015, debido a las circunstancias y dificultades con las que trabajábamos, teníamos ordenadores plataformas que no nos permitían instalar nada y como tarea teníamos que hacer cruce de información de grandes ficheros .csv con sistemas de bases de datos relacionales. Los ficheros .csv eran tan grandes que ni siquiera podíamos visualizarlos con excel ni con atom y apache drill termino siendo una herramienta estupenda para poder realizar exploración sobre los datos y eso que lo utilizamos en modo embebido en nuestro ordenadores.
Instalación
Apache drill tiene 2 tipos de instalación dependiendo si será en un cluster o si será en un único nodo, nosotros haremos la de un único nodo, la cual es muy sencilla ya que solo es necesario descomprimir el fichero descargado y ejecutar el fichero ./drill-embebed el cual esta en la carpeta /bin de nuestra instalación.
Este último paso abrirá una consola donde podremos ejecutar sentencias sql y además se levantará un cliente web al que podremos acceder desde cualquier navegador en la ruta http://localhost:8047
apache drill web client
Ahora vamos a empezar a jugar con drill, para ello crearemos un fichero json que denominaremos cliente_banco.json con los siguientes datos:
|
|
{"ID": "12121212","BANCO": "BANCO_A"} {"ID": "12312312","BANCO": "BANCO_B"} {"ID": "13131313","BANCO": "BANCO_C"} {"ID": "23423423","BANCO": "BANCO_A"} |
También crearemos un fichero csv con los datos de los clientes y lo llamaremos clientes.csv:
|
|
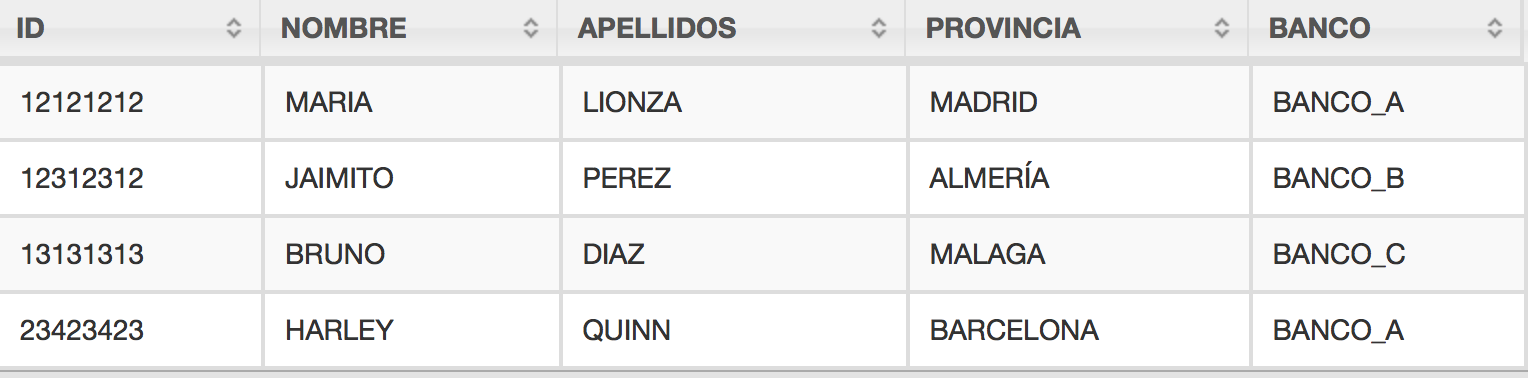
"ID", "NOMBRE", "APELLIDOS", "PROVINCIA" "12121212", "MARIA", "LIONZA", "MADRID" "12312312", "JAIMITO", "PEREZ", "ALMERÍA" "13131313", "BRUNO", "DIAZ", "MALAGA" "23423423", "HARLEY", "QUINN", "BARCELONA" |
Ahora que empiece la diversión, lo primero que haremos será consultar los datos del fichero clientes.csv como si fuera una tabla con SQL utilizando el cliente Web de drill, para ello será necesario ir a la ruta http://localhost:8047/query
Una vez allí ejecutaremos la siguiente sentencia:
SELECT * FROM dfs.ruta_fichero/clientes.csv

resultado query csv en drill
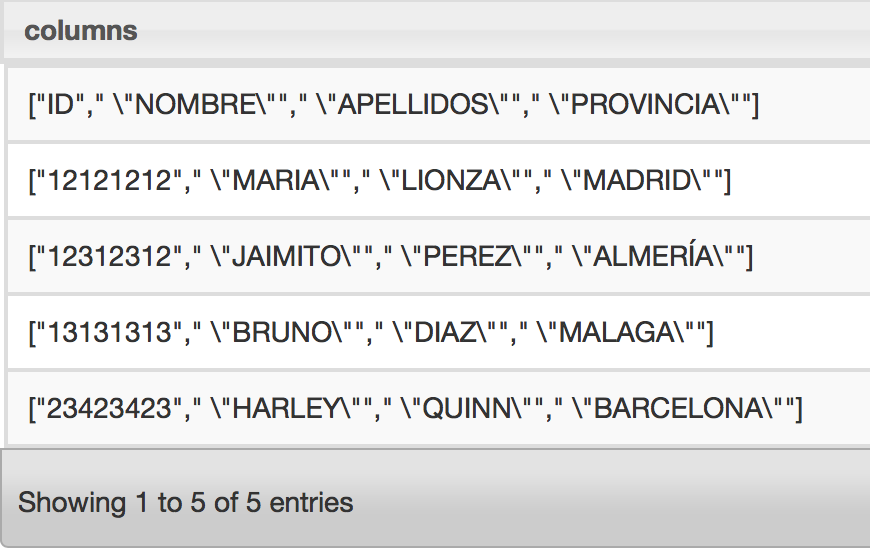
El resultado no se puede apreciar muy bien además que se ve que asume la cabecera del fichero csv como si fuese un registro, para mejorar esto, será necesario hacer una pequeña modificación en la configuración. Apache drill funciona con plugins donde se almacena toda la configuración de las conexiones con ficheros del filesystem, de gestores de bases de datos, tipo mongoDB, MySQL, etc. por ende será necesario que editemos la configuración del plugin de filesystem para que tome en cuenta la cabecera del fichero csv (NOTA: Aquí también podríamos configurar el tipo de separador ya sea «,»o «;» o «|» entre otros).
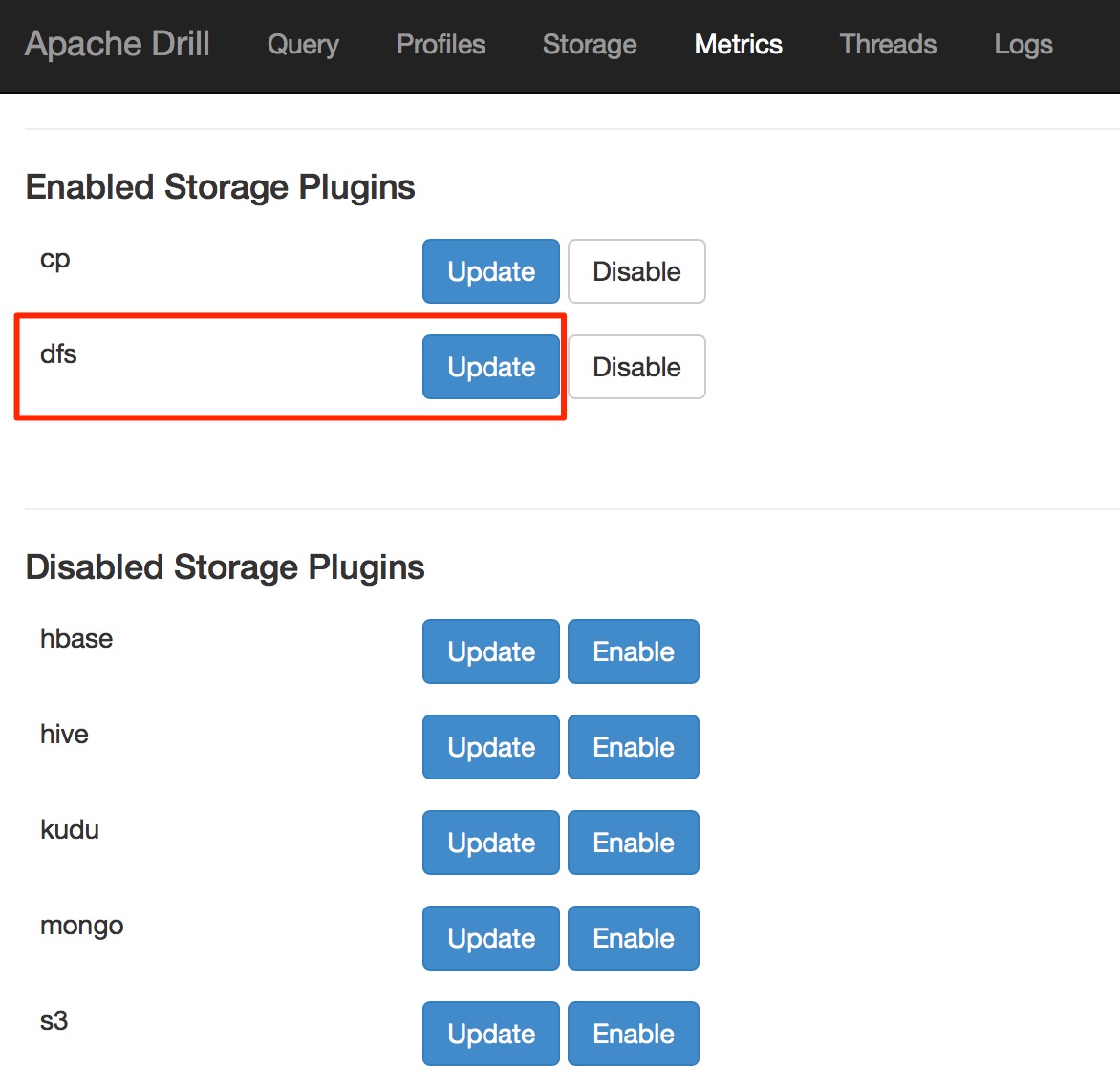
Para realizar la actualización de la configuración deberemos ir a la ruta http://localhost:8047/storage y hacer clic en el botón «Update» del plugin dfs.
storage
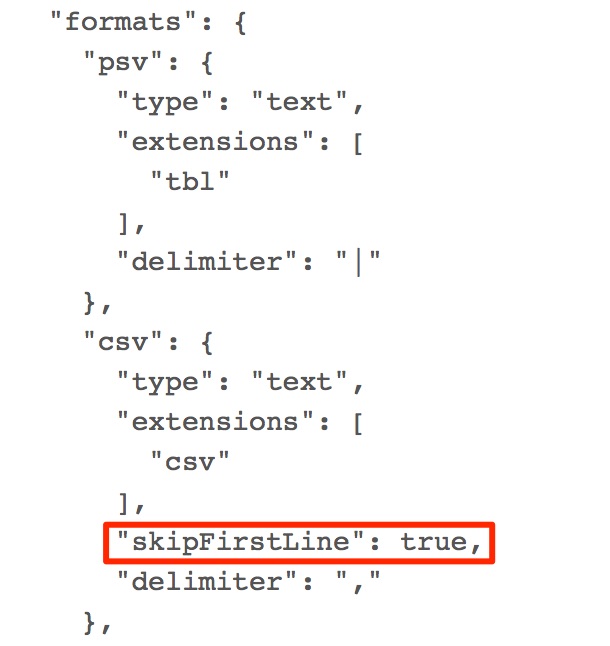
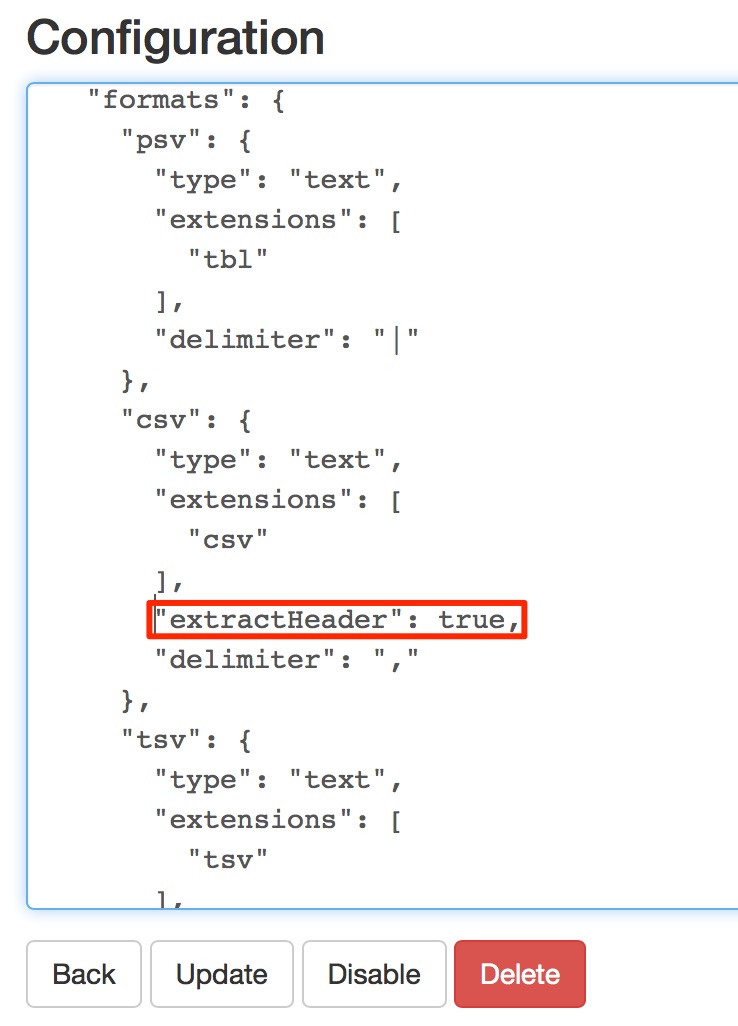
Allí veremos un json utilizado para la configuración y buscaremos el elemento «csv» dentro del objeto «formats» y le añadiremos el atributo «skipFirstLine»: true como se muestra en la siguiente imagen y procederemos a actualizar el plugin pulsando el botón «Update».
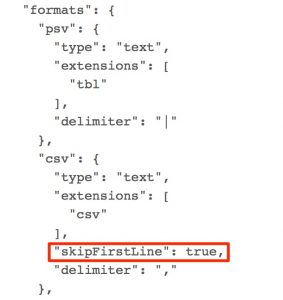
configurando plugin dfs para que no tome en cuenta la primera linea del csv
Si intentamos de nuevo la consulta veremos como es obviada la cabecera del fichero csv, aunque aún no vemos el resultado como una tabla, para eso utilizaremos alias para identificar a cada columna al momento de efectuar la consulta de la siguiente forma:
SELECT columns[0] as ID, columns[1] as NOMBRE, columns[2] as APELLIDOS, columns[3] as PROVINCIA FROM dfs.ruta_fichero/clientes.csv
Obteniendo lo siguiente:
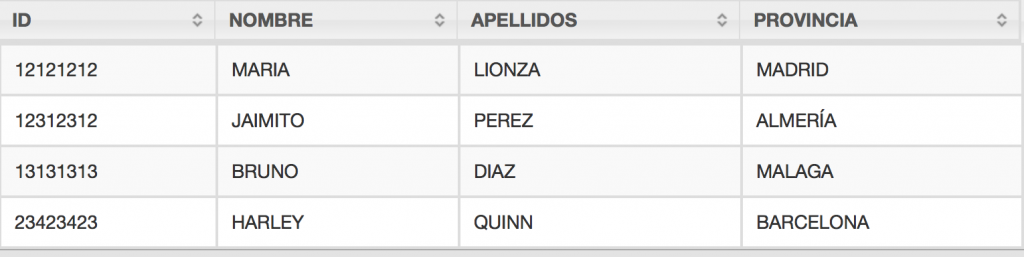
resultado de la consulta
Vamos a profundizar aún más y ahora realizaremos un join entre los datos del fichero csv y del fichero json, ejecutando la siguiente consulta:
SELECT tablaCSV.columns[0] as ID, tablaCSV.columns[1] as NOMBRE, tablaCSV.columns[2] as APELLIDOS, tablaCSV.columns[3] as PROVINCIA, tablaJSON.BANCO FROM dfs.ruta_fichero/clientes.csv
LEFT JOIN dfs..ruta_fichero/cliente_banco.json
ON tablaCSV.columns[0] = tablaJSON.ID
Obteniendo:
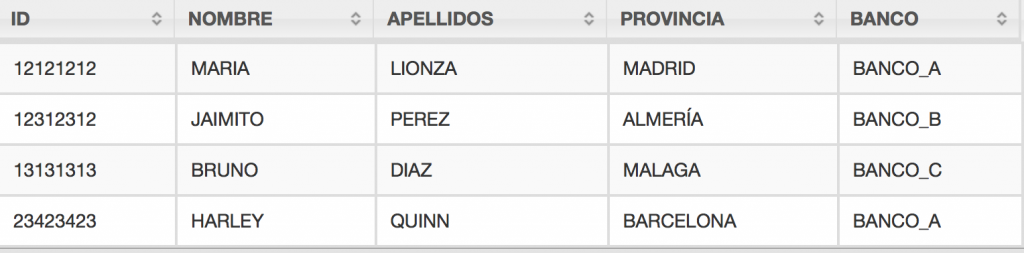
resultado del left join
Apache drill nos ofrece a su vez más posibilidades como por ejemplo crear tablas en formato parquet a partir de un json o de un fichero csv. Apache drill es una herramienta que me gusta mucho pero también cuenta con algún aspecto a mejorar, por ejemplo me gustaría poder utilizar la cabecera de un fichero csv como nombre de columna al efectuar consultas y esto no funciona del todo bien, de hecho hice unas pruebas y fue así como me percate de este pequeño error que estoy seguro (y espero) se solucione pronto.
Para que la cabecera de un archivo csv sea tomada en cuenta como nombre de columna de una tabla es necesario modificar la configuración del plugin dfs, al igual que lo hicimos antes para que no tomase en cuenta la primera fila del archivo, editando el formato csv así como en la siguiente imagen.
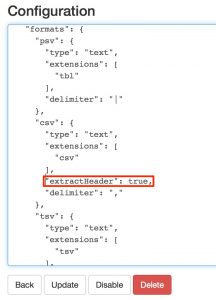
configurando dfs plugin para que reconozca la cabecera de los ficheros csv
De nuevo repitamos la consulta que hacíamos al principio:
SELECT * FROM dfs.ruta_fichero/clientes.csv
Vemos como de inmediato sin haber utilizado alias en la consulta el resultado es devuelto como una tabla
Si ahora repetimos la consulta veremos como la salida de los resultados ha cambiado, dándonos una perspectiva de que tenemos una tabla, utilizando la cabecera del fichero csv como la cabecera de la tabla de resultados
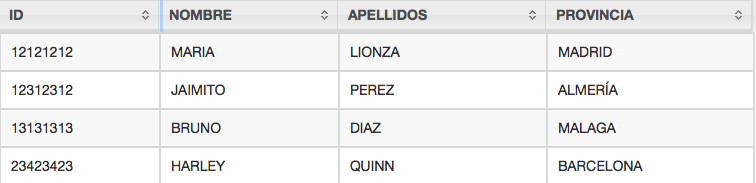
consulta de todos los campos
Además al igual que con ejemplos anteriores podemos efectuar join con otras tablas independientemente en el formato o fuente que se encuentren (son, csv, parquet, mysql, etc…), el problema (o error) esta cuando intentamos consultar por un campo en especifico alguno puede que no devuelva nada como por ejemplo si efectuamos la siguiente consulta:
SELECT ID, NOMBRE FROM dfs.ruta_fichero/clientes.csv
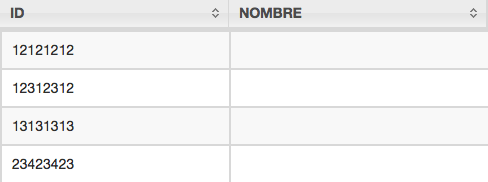
consulta de ID y NOMBRE
Esto me pareció tan extraño que intente jugar con distintos parámetros de configuración e incluso con la forma de realizar la consulta y no pude solventar este comportamiento por lo que publiqué este error en stackoverflow por si estaba haciendo algo mal y alguien podía echarme una mano.
No quiero que lo último los desanime a probar la herramienta ya que esta cuenta con muchas bondades que dan para redactar unas cuantas entradas más, espero que hayan podido seguir todos los ejemplos y tener una perspectiva de lo que podemos alcanzar con la herramienta.
ACTUALIZACIÓN 28-09-2016:
Al haber quedado con la inquietud del mal funcionamiento al ejecutar la consulta sobre el csv indicando como columnas la cabecera del fichero, me decidí a escribir a lista de usuarios de apache drill por si en dado caso me estaba topando con un bug (cosa extraña porque llevaría así al menos 3 releases) y ellos me han dado la respuesta, el problema estaba en el espacio en blanco inmediatamente después de la coma, por lo cual al reformular la consulta y hacerla de la siguiente manera funcionó a la perfección:
SELECT ID, ‘ NOMBRE’ FROM dfs.ruta_fichero/clientes.csv
Pero otra forma quizás más elegante aún es que se eliminase el espacio después de la coma en la cabecera del archivo csv, de esa manera basta con que coloquemos los nombres de las columnas sin necesidad de encerrarlas entre comillas al momento de formular la consulta.
SELECT ID, NOMBRE FROM dfs.ruta_fichero/clientes.csv