
Hoy de nuevo les traigo a ustedes un post relacionado con Apache Drill. Como les comenté en el post anterior, apache drill funciona con plugins, donde en cada uno de estos se define como se establece la conexión. Por ende en este caso nosotros deberemos crear un plugin para conectarnos con MySQL. De nuevo utilizaremos el modo embebed de la herramienta por lo cual para iniciar deberemos ir a la carpeta bin dentro de la instalación de apache drill y ejecutar el archivo drill-embedded en el caso de aquellos que estén utilizando Windows deben ejecutar sqlline.bat.
Desde un navegador web nos vamos a la dirección
http://localhost:8047/storage
Ruta donde están los plugin de antemano definidos. Para crear nuestro nuevo plugin para conectarnos con MySQL nos iremos a la parte inferior y en el campo de texto le daremos el nombre del nuevo plugin a crear, en nuestro caso lo llamaremos mysql y pulsaremos el botón «Create».
create plugin
Inmediatamente después en el campo «Configuration» introducimos el siguiente json eliminando el null que trae por defecto y pulsamos el botón «Create»
|
1 2 3 4 5 6 7 8 |
{ "type": "jdbc", "driver": "com.mysql.jdbc.Driver", "url": "jdbc:mysql://localhost:3306", "username": "username", "password": "mypassword", "enabled": true } |
donde:
username: será el nombre de usuario que utilizamos para conectarnos a MySQL.
password: será el password que utilizamos para conectarnos a MySQL.
url: El host y el puerto al que nos conectamos en MySQL.
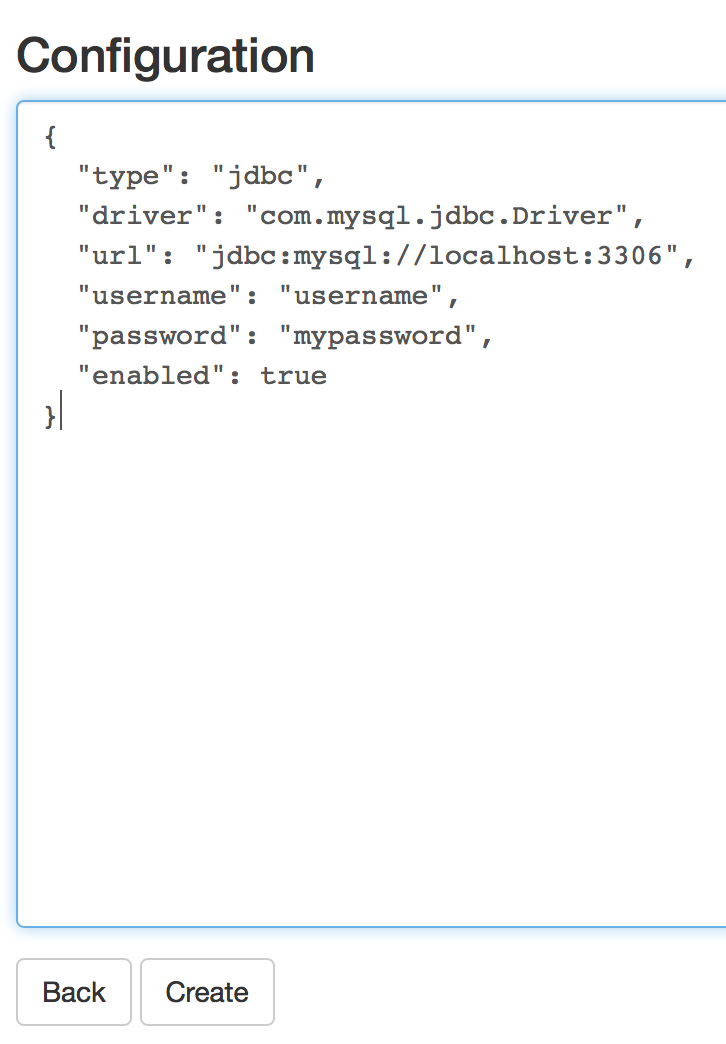
configuración del plugin
El siguiente paso es colocar jar driver mysql en la ruta <drill_installation_directory>/jars/3rdparty
Hay un último paso a llevar a cabo en la configuración, para que la definición del plugin se mantenga una vez hayamos reinciado el ordenador o iniciado una nueva sesión con drill.
Editaremos el fichero <drill_installation_directory>/conf/drill-override.conf y especificaremos la ruta donde se almacenarán las configuraciones (definiciones) que hagamos de los plugins por ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 |
drill.exec: { cluster-id: "drillbits1", zk.connect: "localhost:2181", sys.store.provider: { local: { path: "/tmp/drill", write: true } }, } |
Una vez hecho esto si reiniciamos drill veremos en los storage el plugin de mysql. Por último para comprobar la definición del plugin solo necesitaremos efectuar una consulta por ejemplo utilizando el UI de apache drill de la forma:
SELECT * mysql.database_name.table_name
Al igual que con el post anterior una vez definido el plugin de mysql podremos efectuar consultas del tipo join que involucren una tabla en MySQL, un fichero CSV, un fichero JSON y otros.