
Sigo con mi pruebas con lo nuevo (y no tan nuevo de Spark 2), hoy comparto con ustedes una versión 2 de mi anterior post Estadística simple con Spark, pero en esta ocasión realizado con Spark 2.
¿Que tiene de nuevo esta versión?
Primeramente utiliza el módulo spark-csv lo cual nos hace más simple la carga del fichero en un Dataset. Segundo, que no manipulamos en ningún instante RDD alguno, sino que por el contrario estamos trabajando con DataFrames representados mediante la clase Dataset. Entre las cosas nuevas que contempla esta versión hecha en Spark 2 es que mientras antes al realizar un groupBy sobre un DataFrame esto nos devolvía un GroupedData ahora nos devuelve un RelationalGroupedData, esto debido a un cambio de nombre que se le ha dado a partir de esta nueva versión de Spark.
Esta nueva versión realizada con SparkSQL con Datasets tiene varias ventajas, la primera es simplicidad, es mucho mas simple, mas fácil de entender el código además de mas corto, de hecho con menos lineas obtuve más información que con la versión elaborada con RDD’s, es decir, es mas versátil. Por otro lado aunque hay que tener algo de nociones de conjuntos lo interesante es que esta versión esta libre de código SQL.
Sin más dilación he aquí el código y el enlace al proyecto en Github.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
package com.josedeveloper import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ object SimpleStatisticsWithSparkV2 extends App { val sparkSession = SparkSession.builder. master("local") .appName("Simple Application") .getOrCreate() //custom scheme definition val customSchema = StructType(Array( StructField("COD_DISTRITO", StringType, true), StructField("DESC_DISTRITO", StringType, true), StructField("COD_DIST_BARRIO", StringType, true), StructField("DESC_BARRIO", StringType, true), StructField("COD_BARRIO", StringType, true), StructField("COD_DIST_SECCION", StringType, true), StructField("COD_SECCION", StringType, true), StructField("COD_EDAD_INT", StringType, true), StructField("EspanolesHombres", IntegerType, true), StructField("EspanolesMujeres", IntegerType, true), StructField("ExtranjerosHombres", IntegerType, true), StructField("ExtranjerosMujeres", IntegerType, true))) val df = sparkSession.read.format("com.databricks.spark.csv") .format("com.databricks.spark.csv") .option("header", "true") .option("delimiter" , ";") .option("nullValue", null) .schema(customSchema) .load("src/main/resources/Rango_Edades_Seccion_201506.csv") df.show(true) //fill empty values with 0 val dfNA = df.na.fill(0, Seq("EspanolesHombres","EspanolesMujeres","ExtranjerosHombres","ExtranjerosMujeres")).cache() dfNA.show(true) dfNA.groupBy("DESC_DISTRITO") .agg(avg("EspanolesHombres"), avg("EspanolesMujeres"), avg("ExtranjerosHombres"), avg("ExtranjerosMujeres")) .show() dfNA.groupBy("DESC_DISTRITO") .agg(max("EspanolesHombres"), stddev("EspanolesHombres"), max("EspanolesMujeres"), stddev("EspanolesMujeres")) .show() val dfNASum = dfNA.groupBy(df("DESC_DISTRITO")) .sum("EspanolesHombres","EspanolesMujeres","ExtranjerosHombres","ExtranjerosMujeres").cache() //Total of people per district dfNASum.select(dfNASum("DESC_DISTRITO"), (dfNASum("sum(EspanolesHombres)") + dfNASum("sum(EspanolesMujeres)") + dfNASum("sum(ExtranjerosHombres)") + dfNASum("sum(ExtranjerosMujeres)")).alias("total")) .sort(asc("total")) .show(30) } |
Para que comparen los resultados obtenidos aquí con respecto a la entrada anterior dejo un pantallazo de lo obtenido al ejecutarlo en mi local.
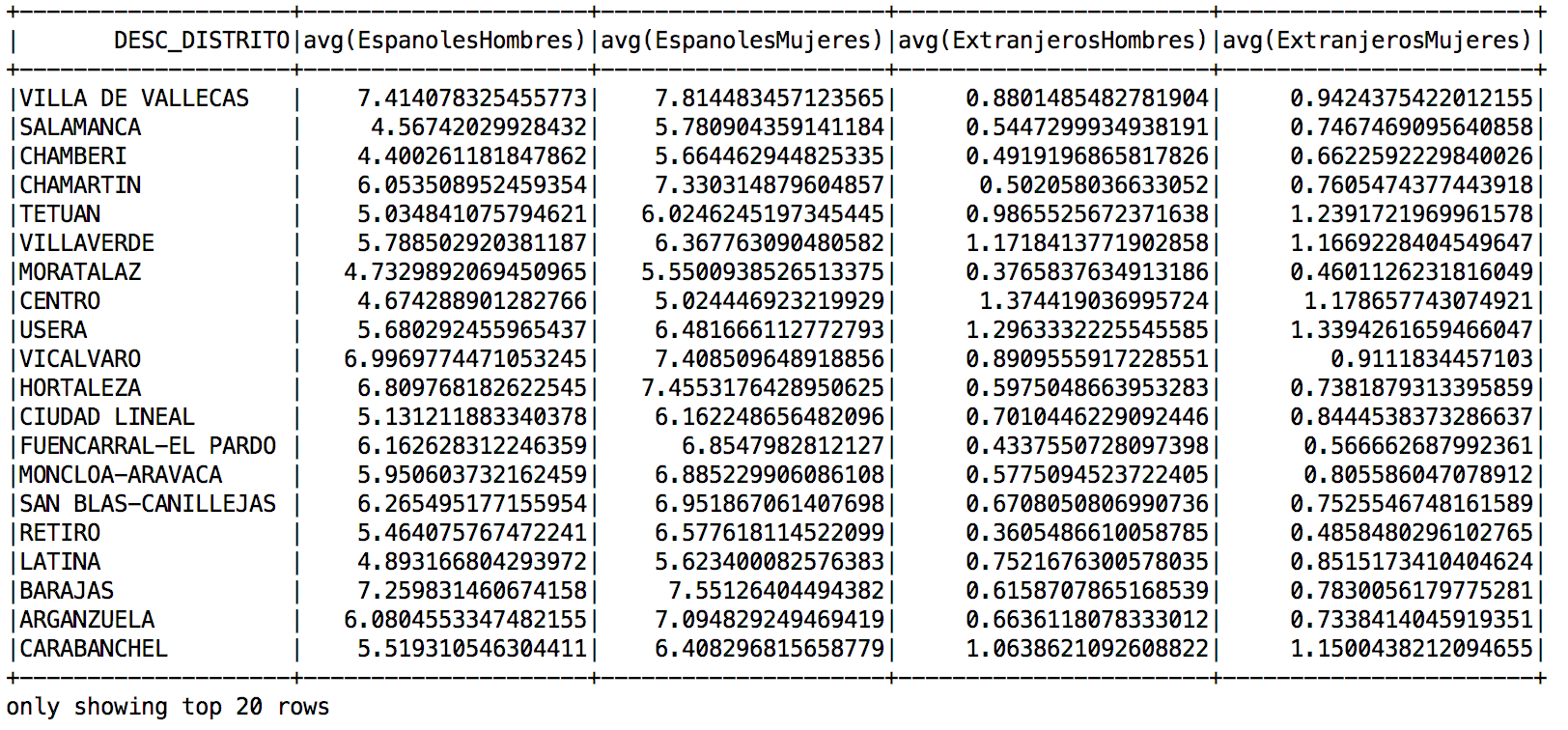
promedios por distrito

Otras agregaciones por distrito

Total personas por distrito
